
Web scraping: How to handle a calendar with Selenium
https://towardsdatascience.com/web-scraping-how-to-handle-a-calendar-with-selenium-862ce689a7d7
Web scraping: How to handle a calendar with Selenium
Learning to use Python tools to scrape the web
towardsdatascience.com
I was just trying to scrape historical data on a particular website. This page has always the same URL. But when you pick a different day from the calendar, the content changed.
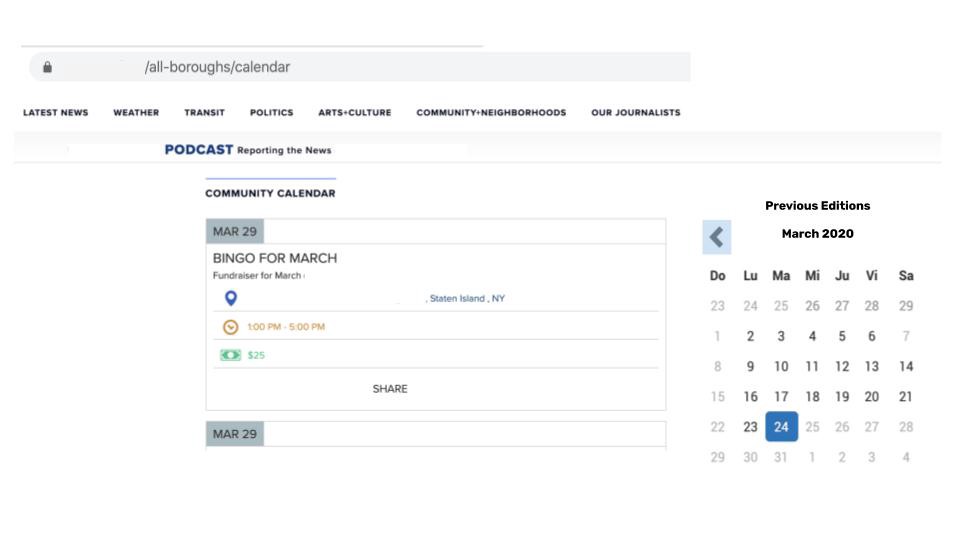
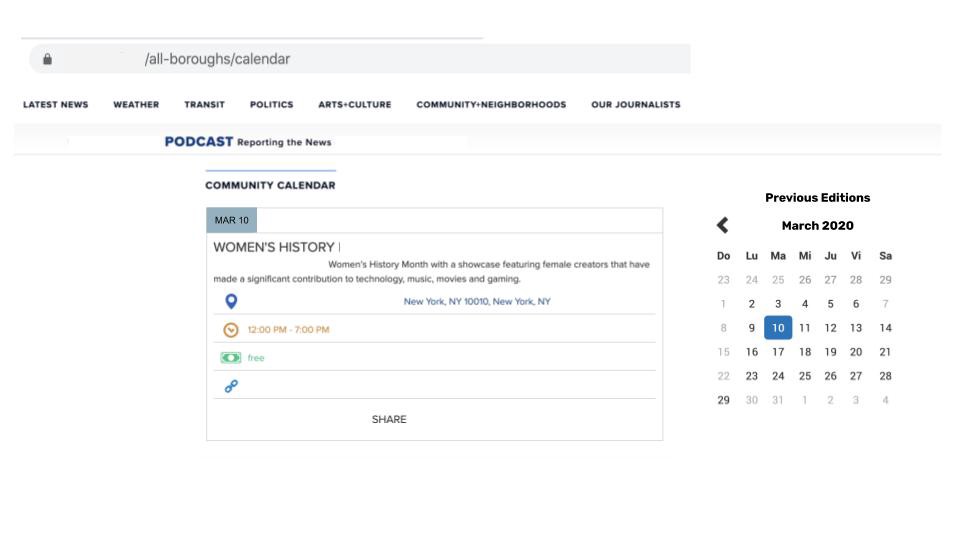
If you select a new date, the content will change. However, the URL address will remain the same.
I was really struggling. I have previously built scrapers using Scrapy (If you want to learn more, read my previous post).
But I knew that this Python framework has some limitations. One of them is dealing with Javascript.
I decided to stop surfing the channels. I started reading and suddenly, I found the solution: Selenium.
Selenium is a tool that comes in handy for Web Browser Automation. It is able to open a browser of choice and mimics human behavior.
This means that it can perform tasks such as clicking buttons, filling forms or searching for information on a website. That’s cool, right?
Installing the packages is also very easy. We need to use the normal pip syntaxis: pip install selenium .
But there is an extra step that needs to be done. We need to download Chrome Driver. This WebDriver is an open-source tool for automated testing that provides capabilities for navigating to web pages, user input, JavaScript execution, and more.
Pay attention to download the version of ChromeDriver that is compatible with the version of your browser
Let’s start coding!
First of all, we’ll import the modules we need.
- The module re to work with Regular Expressions
- BeautifulSoup to pull the data from the Website
- selenium.webdriver to launch the browser
- selenium.webdriver.ActionChains to automate low-level interactions such as mouse movements.
After that, we need to create a new instance of google chrome.
We’ll use webdrive.Chrome() passing as argument the exact path that points where we downloaded the ChromeDrive.
Then, we use the .get() method passing as argument the desired URL.
If we run this, we’ll see that a new window is opened displaying the legend Chrome is being controlled by automated test software.
The first thing to do when scraping a website is to understand the structure of the website. Particularly, how we indicate Selenium how to select the different dates.
Let’s inspect the webpage HTML code, focusing on the calendar element.
We want to scrap the content of the website for the last two years. There are many strategies that can be followed here.
We’ll just indicate to WebDriver to click the previous <button n times. So if we are in March 2020 and we want to go to March 2018, we should press the button 24 times.
Let’s refresh our knowledge about XPath.
XPath stands for XML Path Language. What does it have to do with web scraping? We’ll learn how to identify HTML elements. But the question that arises now is how do I point out the element to the scraper? And the answer is XPath.
XPath is a special syntax that can be used to navigate through elements and attributes in an XML document. Also, it will help us get a path to a certain HTML element and extract its content.
Let’s see how this syntax works.
/ is used to move forward one generation, tag-names gives the direction to which element, [] tell us which of the siblings to choose, // looks for all future generations, @ selects attributes, * is a wildcard indicating we want to ignore tag types?
If we see the following XPath:
Xpath = '//div[@class="first"]/p[2]'we would understand that from all (//) the div elements with class “first” (div[@class="first"]), we want the second ([2]) paragraph (p) element.
Fortunately, web browsers have an easy way to get the XPath of an element.
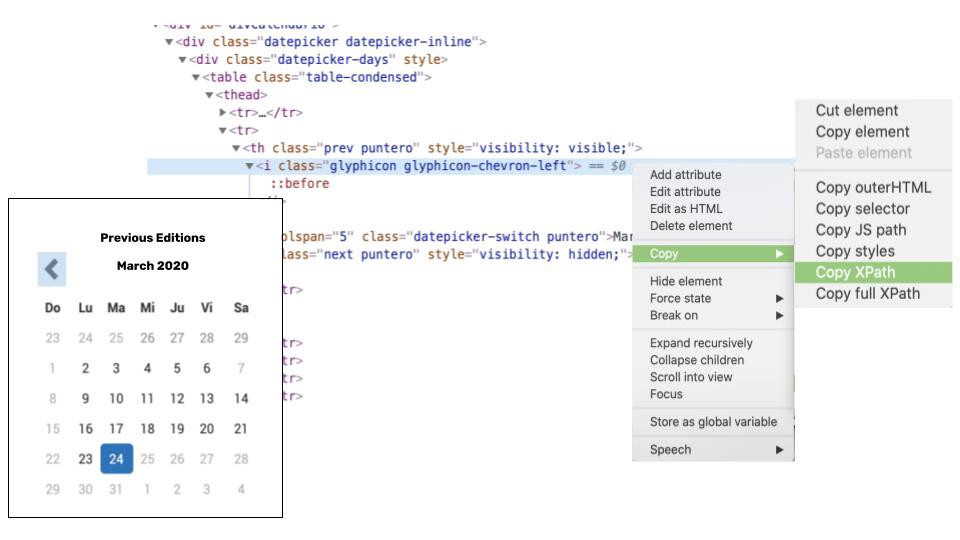
We copy the XPath of the element and pass it to the function .find_element_by_xpath().
Now, it’s time to tell WebDriver to go and click this element. We do that by chaining from ActionChains()the following functions:
- .click() that will click on the element
- .perform() that will perform the action
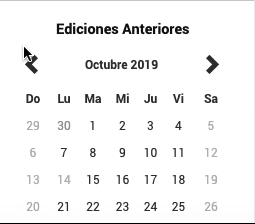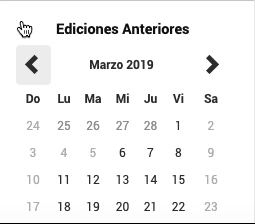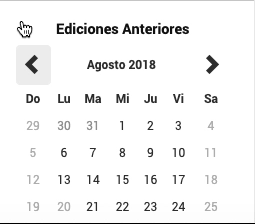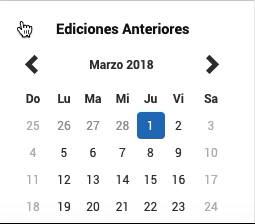
How web driver should go back on time
Once the calendar has gone back in time 24 months, we should tell selenium to click each day and scrape the content.
To understand how to point to the day element, let’s again inspect the website.
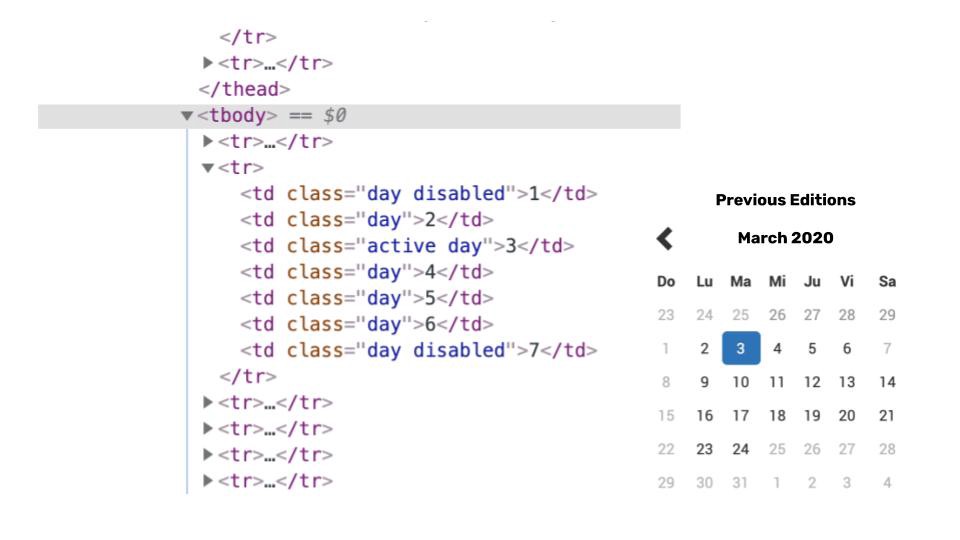
Look a the HTML code. We can observe that the different date attributes have different class values assigned.
The days that appeared in grey, have the day disable class. The day that is in black, have the class day , and the selected day (current date) have the class active day .
This last class will be unique to the current date attribute so we can use it to select the current date from the calendar.
First, we will make a list of all the elements with a class attribute containing the word day .
This time, we’ll point towards those elements using the function .find_element_by_class_name(). This comes in handy when we want to locate an element by class attribute name.
Once we have that list, we’ll loop over the list. For each element that we found, we get its attribute and ask if it is strictly equal to day . If it is, we’ll tell webdriver to click on it.
We’ll wait 5 seconds so the website can be loaded.
After that, we’ll use BeautifulSoup to scrape through the website. Here, it’s where we can insert any code to scrap the content of the website. We can just use find() or findall() methods.
Once we scrap the content, the loop we’ll move to the next day element found.
Notice that we need to do this for each month. So once all the elements of the month have been looped over, we need to move to the next month. The procedure is exactly the same as we did with the previous button.
Now, we save this script in a file (e.g. selenium_script.py). To run the script and start scrapping, we open a new terminal window.
We need to go to the same folder we have the file and type:
python3 selenium_script.py
After that, a Chrome window will pop up. And start to automatically click on the different dates. We will see something like this:
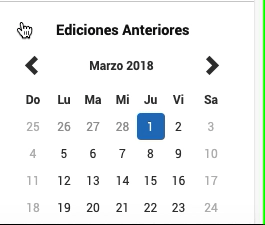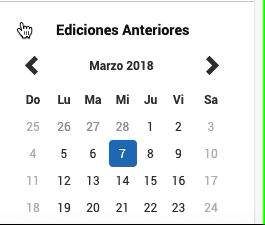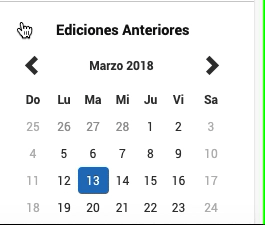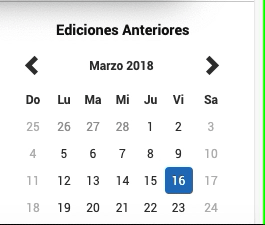
The web driver will simulate selecting the different dates
Once all the website and dates have been scrapped, we will see the following message in the terminal:
Process finished with exit code 0
This means that everything went well, and no error was encountered.
If we specified a file to save the content of the website, we can now go to the file and check the scrapped content.
'웹 크롤링, 스크래핑' 카테고리의 다른 글
| Microsoft Edge Web Driver 공식 다운로드 사이트 (0) | 2022.06.21 |
|---|---|
| BeautifulSoup, HTML 구조에서 특정 태그의 요소 다루기 (0) | 2022.06.18 |
| BeautifulSoup, selenium 크롤링, 스크래핑 (0) | 2022.06.17 |
| chromedriver.exe 다운로드(download) 사이트 (0) | 2021.05.18 |
| 파이썬, 네이버 오늘의 코스피 코스닥 지수 가져와 출력하기 (0) | 2020.01.06 |