
[출처] https://towardsdatascience.com/deploy-models-and-create-custom-handlers-in-torchserve-fc2d048fbe91
PyTorch에서 모델 배포
PyTorch는 모델을 제공하기 위해 torchserve.So라는 새로운 프로덕션 프레임워크를 도입했습니다.
- 도커로 설치
- 모델 내보내기
- 핸들러 정의
- 모델을 서비스하기
토치서브를 보여주기 위해 잘 훈련된 ResNet34를 이용하여 이미지 분류를 수행할 것입니다.
도커로 설치
공식 문서는 여기를 참고하세요.
토치서브를 설치하는 가장 좋은 방법은 도커를 사용하는 것입니다. 도커 이미지를 끌어오기만 하면 됩니다.
다음 명령을 사용하여 최신 이미지를 저장할 수 있습니다.
docker pull pytorch/torchserve:latest모든 태그는 여기에서 사용할 수 있습니다. 도커 및 토치서브에 대한 자세한 내용은 여기 참조하세요.
핸들러
공식 문서는 여기를 참고하세요.
핸들러는 하나 이상의 HTTP 요청에서 모델을 사용하여 예측을 수행하는 역할을 합니다.
기본 핸들러 Default handlers
Torchserve는 다음과 같은 기본 핸들러를 지원합니다.
- image_classifier
- object_detector
- text_classifier
- image_segmenter
커스텀 핸들러 Custom handlers
토치서브는 다양한 작업을 수행할 수 있는 풍부한 인터페이스를 제공합니다. 핸들러는 세 가지 기능이 있어야 하는 클래스입니다.
- 전처리 preprocess
- 추론(예측) inference
- 후처리 postprocess
자신의 클래스를 만들거나 BaseHandler의 하위 클래스를 만들 수 있습니다. BaseHandler 서브클래싱 장점은 로드된 모델을 self.model에서 액세스할 수 있다는 것입니다. 다음 코드는 BaseHandler 서브클래스 사용을 방법을 보여줍니다.

이미지 분류 예제로 돌아가서 우리는 다음 사항을 진행해야 합니다.
- 각 요청에서 이미지를 가져와 사전 처리하기
- 모델에서 예측한 내용 가져오기
- 요청자에게 응답하기
전처리 Preprocess
preprocess 함수는 요청(request) 배열을 가져옵니다. 이미지를 서버로 보낸다고 가정하면 직렬화된 이미지는 요청 data또는 body 필드에서 접근할 수 있습니다. 따라서 모든 요청을 반복하면서 각 이미지를 개별적으로 사전 처리할 수 있습니다. 전체 코드는 아래에 있습니다.

self.transform은 전처리 변환(transformation)입니다. ImageNet에서 훈련된 모델을 위한 고전적인 전처리 단계입니다.
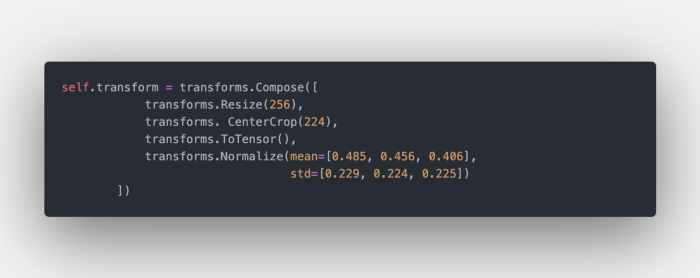
각 요청에서 각 이미지를 사전 처리한 후 이를 연결하여 pytorch Tensor를 만듭니다.
추론 Inference

이 단계는 매우 쉽습니다. .preprocess 함수에서 텐서를 가져 오고 각 이미지에 대한 예측을 추출합니다.
후 처리 Postprocess
각 이미지에 대한 예측을 구했으므로 클라이언트에게 무언가 반환해야 합니다. Torchserve는 항상 배열이 반환될 것으로 예상합니다. BaseHandler 또한 index -> label 매핑(self.mapping)을 가진 .json 파일에 열어서 저장합니다. 각 label및 index와 관련된 예측 사전 배열(res)을 반환할 수 있습니다.

이러한 것을 모두 가진 핸들러의 전체 모습은 다음과 같습니다.
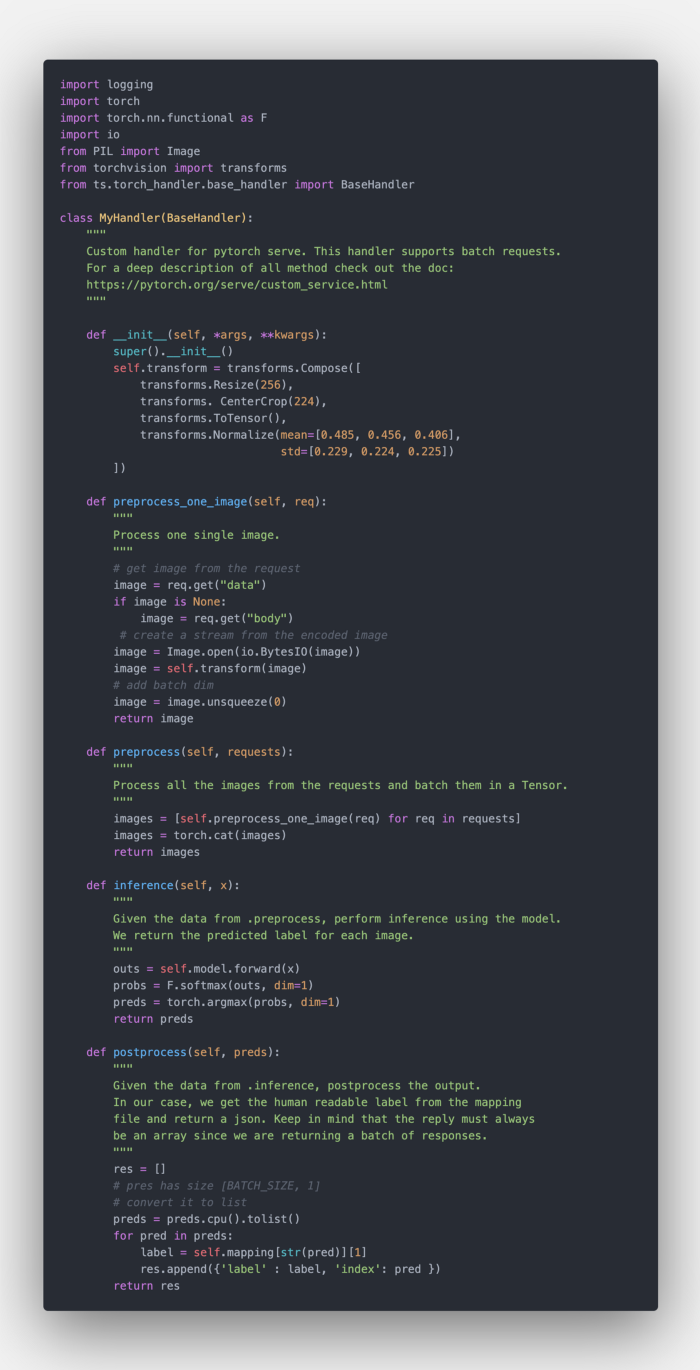
모든 처리 로직이 클래스에 모여 있으므로 단위 테스트를 쉽게 할 수 있습니다!
모델 내보내기
공식 문서는 여기를 참고합니다.
Torchserve는 .mar 파일이 제공될 것으로 예상합니다 . 이 파일은 모델이며 모든 종속성이 함께 포장되어 있습니다.
모델 내보내기 Export the model
토치서브용으로 모델을 내보내는 세 가지 방법이 있습니다. 가장 좋은 방법 모델을 trace 하고 결과를 저장하는 것입니다. 그렇게 하면 토치서브에 파일을 추가할 필요가 없습니다. 예를 들어 완전히 훈련된 ResNet34 모델을 배포할 것입니다.

진행 순서:
- 모델 로드
- 더미 입력 생성
- torch.jit.trace 사용하여 모델을 통한 입력 추적
- 모델을 저장
.mar 파일 만들기
공식 문서는 여기를 참고합니다.
torch-model-archiver를 설치합니다.
git clone https://github.com/pytorch/serve.git
cd serve/model-archiver
pip install .
그 다음 다음 명령을 사용하여 mar 파일을 만들 준비를 합니다.
torch-model-archiver --model-name resnet34 \
--version 1.0 \
--serialized-file resnet34.pt \
--extra-files ./index_to_name.json,./MyHandler.py \
--handler my_handler.py \
--export-path model-store -f
변수 --model-name는 모델의 최종 이름을 정의합니다. 이것은 예측을 담당할 endpoint의 네임스페이스가 되기 때문에 매우 중요합니다. --version을 지정할 수도 있습니다 . --serialized-file는 이전에 만들어 저장된 .pt 모델을 가리킵니다 . --handler는 커스텀 핸들러를 호출하는 파이썬 파일입니다. 일반적으로 다음과 같습니다.

--handler에는 사용자 정의 핸들러(함수)를 지정합니다.
참고로 index_to_name.json 파일을 전달하면 자동으로 핸들러에 로드되고 self.mapping에서 접근할 수 있습니다.
--export-path는 .mar 파일이 저장될 위치이며 -f 옵션은 덮어쓰기입니다.
모든 것이 순조롭게 진행되면 resnet34.mar 파일이 저장된 것을 볼 수 있습니다.
모델 서비스(서빙)
필요한 매개변수를 사용하여 torchserve 도커 컨테이너를 실행할 수 있습니다.
docker run --rm -it \-p 3000:8080 -p 3001:8081 \-v $(pwd)/model-store:/home/model-server/model-store pytorch/torchserve:0.1-cpu \토치서브 --start --model-store 모델-저장 --models resnet34=resnet34.mar컨테이너 포트 8080과 8081을 각각 3000과 3001로 바인딩 시켰습니다(8080/8081은 이미 다른 용도로 사용 중이라 그렇게 했습니다). 그런 다음에 /model-store에 저장할 .mar 파일을 생성합니다. 끝으로 torchserve를 실행할 때 모델이 저장된 경로와 모델( 각 파일의 모델 이름을 지정하는 키-값 쌍 목록과 경로 torchserve를 채워서 호출 합니다.
이제서 토치서브의 /predictions/resnet34에 이미지를 보내 예측을 얻을 수 있습니다. 이것은 다음처럼 리눅스 curl 명령을 사용하여 수행할 수 있습니다.
curl -X POST http://127.0.0.1:3000/predictions/resnet34 -T inputs/kitten.jpg
응답
{
"label": "tiger_cat",
"index": 282
}네, 결과가 잘 나왔습니다.
모든 코드는 여기에 있습니다
<이상>
'TorchServe' 카테고리의 다른 글
| 토치서브 시스템 측정 항목 (System Metrics) (0) | 2021.12.22 |
|---|---|
| TORCHSERVE REST API (0) | 2021.12.22 |
| 토치서브 명령 옵션 사용하기 (0) | 2021.12.20 |
| 토치서브 설치, 대시보드 설치, HTTP 요청 (0) | 2021.12.08 |
| TorchServe로 PyTorch 모델 제공 방법 (영어 동영상) (0) | 2021.12.07 |